LGCPs - An example in one dimension
David Borchers and Finn Lindgren
Generated on 2026-05-26
Source:vignettes/articles/1d_lgcp.Rmd
1d_lgcp.RmdIntroduction
In this vignette we are going to see how to fit an SPDE to one-dimensional point data, i.e. data that consist of the points at which things are located, not the number of points in some area.
Get the data
data(Poisson2_1D, package = "inlabru")Take a look at the point (and frequency) data
ggplot(pts2) +
geom_histogram(aes(x = x),
binwidth = 55 / 20,
boundary = 0, fill = NA, color = "black"
) +
geom_point(aes(x), y = 0, pch = "|", cex = 4) +
coord_fixed(ratio = 1)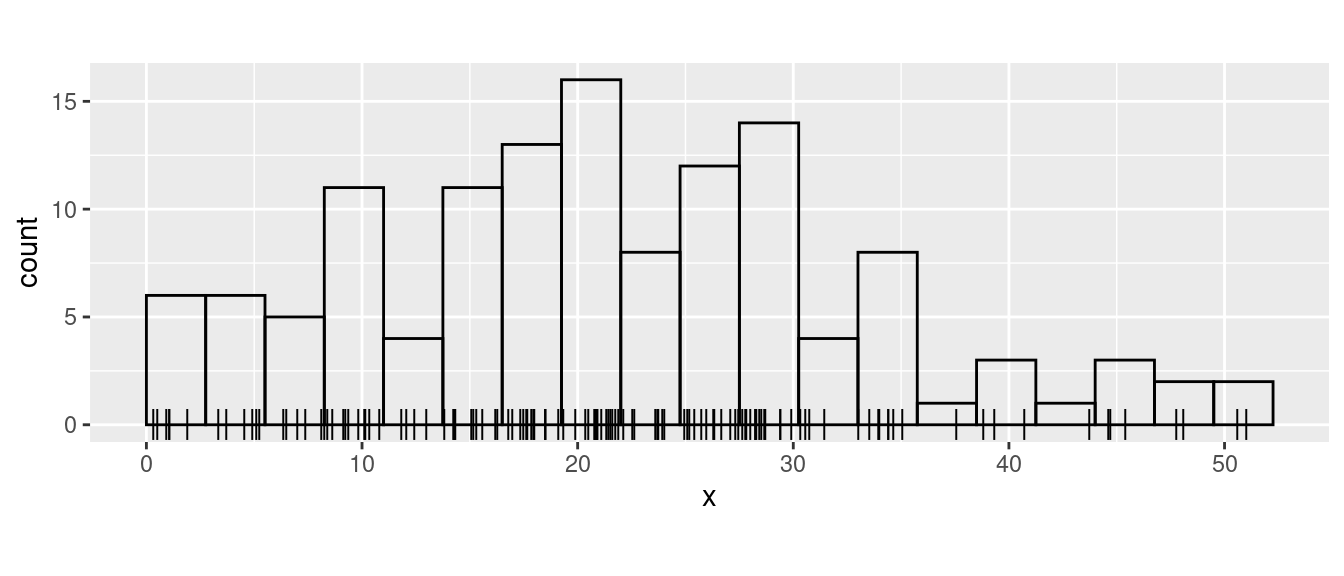
Fiting the model
Build a 1D mesh:
x <- seq(0, 55, length.out = 50)
mesh1D <- fm_mesh_1d(x, boundary = "free")Make the latent components for a 1D SPDE model, using an integrate-to-zero constraint for better identifiability:
matern <- inla.spde2.pcmatern(mesh1D,
prior.range = c(150, 0.75),
prior.sigma = c(0.1, 0.75),
constr = TRUE
)
comp <- ~ spde1D(x, model = matern) + Intercept(1)Here we want to fit to the actual points, and the
inlabru functions that are used for this are
bru() and bru_obs(..., family = "cp"). For
this special case there is also a shortcut function lgcp()
(for ‘Log Gaussian Cox Process’), but it doesn’t support all features.
The standard way of specifying the function space for integration is via
the domain argument.
fit.spde <- bru(
comp,
bru_obs(x ~ ., family = "cp", data = pts2, domain = list(x = mesh1D))
)
## Equivalent call for this particular example:
# fit.spde <- lgcp(
# comp,
# formula = x ~ ., data = pts2, domain = list(x = mesh1D)
# )Here, formula = x ~ . means that the observed points are
in x, and . denotes a linear predictor that is
the sum of all the latent components.
SPDE parameters
We can look at the posterior distributions of the parameters of the
SPDE using the function spde.posterior. It returns
x and y values for a plot of the posterior PDF
in a data frame, which can be printed using the plot
function. To see the PDF for the range parameter, for example:
post.range <- spde.posterior(fit.spde, name = "spde1D", what = "range")
plot(post.range)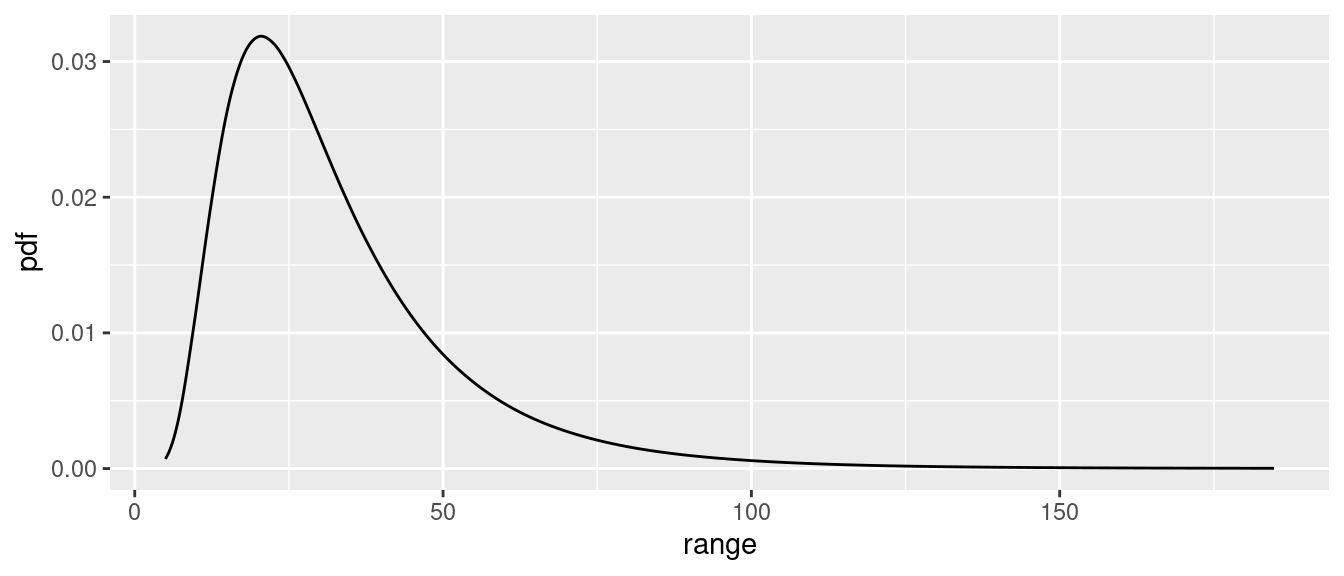
Look at the help file for spde.posterior and then plot
the posterior for the log of the SPDE range parameter, the SPDE variance
and/or log of the variance, and for the Matern covariance function. Make
sure you understand the difference between what is plotted for the range
and variance parameters, and for the covariance function (which involves
both these parameters).
post.log.range <- spde.posterior(fit.spde,
name = "spde1D",
what = "log.range"
)
plot(post.log.range)
post.variance <- spde.posterior(fit.spde,
name = "spde1D",
what = "variance"
)
plot(post.variance)
post.log.variance <- spde.posterior(fit.spde,
name = "spde1D",
what = "log.variance"
)
plot(post.log.variance)
post.matcorr <- spde.posterior(fit.spde,
name = "spde1D",
what = "matern.correlation"
)
plot(post.matcorr)You can get a feel for sensitivity to priors by specifying different priors and looking at the posterior plots.
Predicting intensity
We can also now predict on any scale we want. For example, to predict
on the ‘response’ scale (i.e. the intensity function \lambda(s)), we call predict
thus:
# Set up a data frame of explanatory values at which to predict
predf <- data.frame(x = seq(0, 55, by = 1))
pred_spde <- predict(fit.spde,
predf,
~ exp(spde1D + Intercept),
n.samples = 1000
)while to predict on the linear predictor scale (i.e. that of the log
intensity, \log(\lambda(s))), we call
predict thus:
pred_spde_lp <- predict(fit.spde, predf, ~ spde1D + Intercept, n.samples = 1000)here’s how to plot the prediction and 95% credible interval:
plot(pred_spde, color = "red") +
geom_point(data = pts2, aes(x = x), y = 0, pch = "|", cex = 2) +
xlab("x") + ylab("Intensity")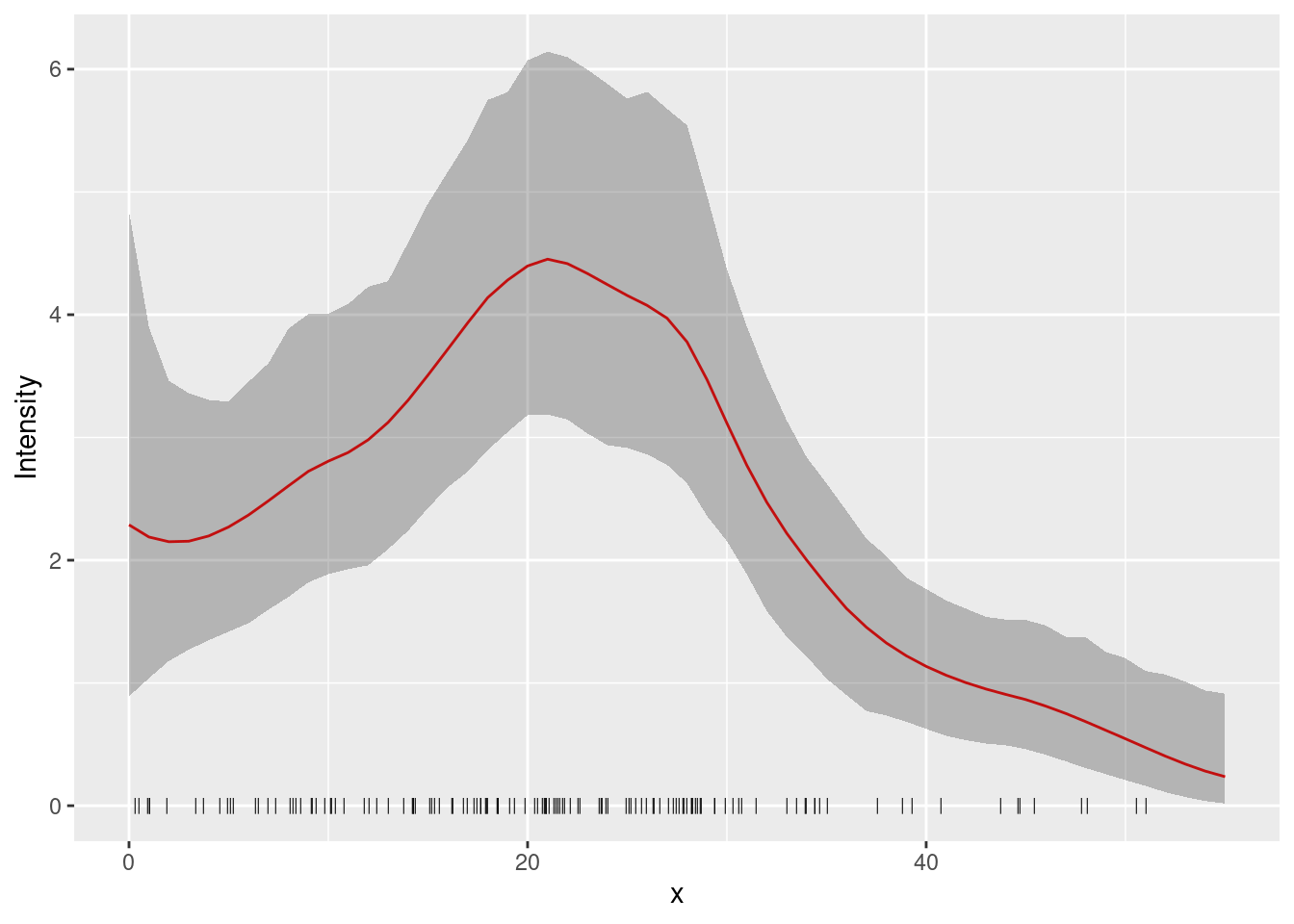
How does this compare with the underlying intensity function that
generated the data? The function lambda2_1D( ) in the
dataset Poission2_1D calculates the true intensity that was
used in simulating these data. In order to plot this, we make a data
frame with x- and y-coordinates giving the
true intensity function, \lambda(s). We
use lots of x-values to get a nice smooth plot (150
values).
xs <- seq(0, 55, length = 150)
true.lambda <- data.frame(x = xs, y = lambda2_1D(xs))Plot the fitted and true intensity functions:
Goodness-of-Fit
We can look at the goodness-of-fit of the mode using the
inlabru function bincount( ), which plots the
95% credible intervals in a specified set of bins along the
x-axis together with the observed count in each bin: The
credible intervals are shown as red rectangles, the mean fitted value as
a short horizontal blue line, and the observed data as black points:
bc <- bincount(
result = fit.spde,
observations = pts2,
breaks = seq(0, max(pts2), length = 12),
predictor = x ~ exp(spde1D + Intercept)
)
attributes(bc)$ggp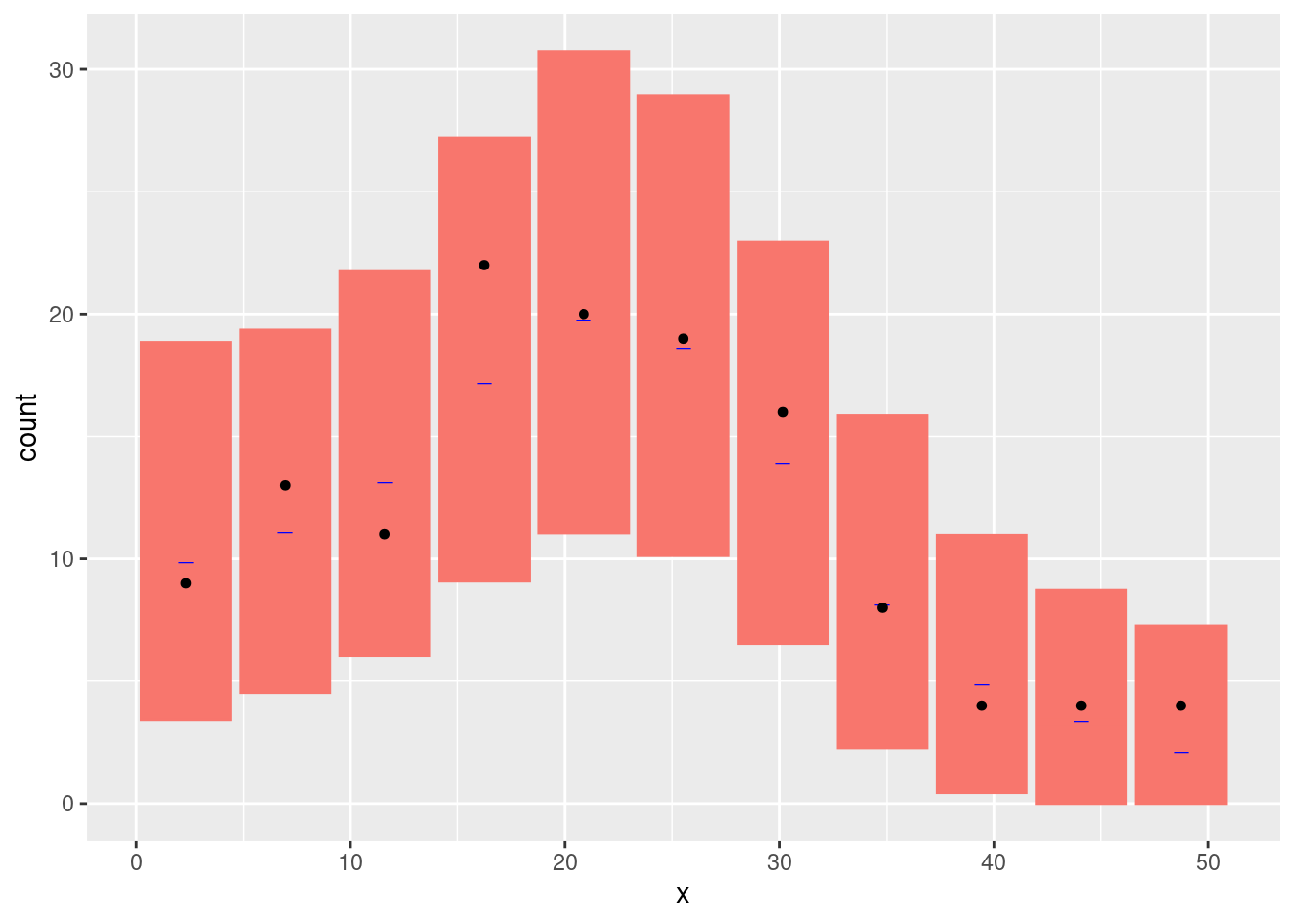
Estimating Abundance
Abundance is the integral of the intensity over space. We estimate it
by integrating the predicted intensity over x. Integration
is done by adding up the intensity at locations x weighted
by a particular weight. The locations x and their weights
are constructed using the fm_int function
ips <- fm_int(mesh1D, name = "x")
head(ips)
#> # A tibble: 6 × 4
#> x weight .block .block_origin[,"x"]
#> <dbl> <dbl> <int> <int>
#> 1 0 0.187 1 1
#> 2 1.12 0.374 1 1
#> 3 2.24 0.374 1 1
#> 4 3.37 0.374 1 1
#> 5 4.49 0.374 1 1
#> 6 5.61 0.374 1 1
Lambda <- predict(fit.spde, ips, ~ sum(weight * exp(spde1D + Intercept)))You can look at the abundance estimate by typing
Lambda
#> mean sd q0.025 q0.5 q0.975 median mean.mc_std_err sd.mc_std_err
#> 1 129.498 11.51532 109.9495 129.8785 148.3663 129.8785 1.304406 0.7643688-
meanis the posterior mean abundance. -
sdis the estimated standard error of the posterior of the abundance. -
cvis its estimated coefficient of variation (stander error divided by mean). -
q0.025andq0.975are the 95% credible interval bounds. -
q0.5is the posterior median abundance
But it is not quite that simple! The above posterior for abundance
takes account only of the variance due to us not knowing the parameters
of the intensity function. It neglects the variance in the number of
point locations, given the intensity function. To include this we need
to modify predict( ) as follows:
Nest <- predict(
fit.spde, ips,
~ data.frame(
N = 50:250,
dpois = dpois(50:250,
lambda = sum(weight * exp(spde1D + Intercept))
)
)
)This calculates the same statistics as were calculated for
Lambda, but for evey value of N from 50 to
250, rather than for the posterior mean N alone:
Nest[Nest$N %in% 100:105, ]
#> N mean sd q0.025 q0.5 q0.975 median mean.mc_std_err
#> 51 100 0.003477738 0.006177508 1.057055e-06 0.001031955 0.02341088 0.001031955 0.0008213561
#> 52 101 0.004014452 0.006747335 1.602975e-06 0.001323345 0.02565326 0.001323345 0.0008806210
#> 53 102 0.004605242 0.007320105 2.407020e-06 0.001680380 0.02783485 0.001680380 0.0009381503
#> 54 103 0.005250907 0.007889424 3.579300e-06 0.002113029 0.02990875 0.002113029 0.0009933698
#> 55 104 0.005951517 0.008448647 5.271360e-06 0.002631526 0.03182818 0.002631526 0.0010457409
#> 56 105 0.006706332 0.008991011 7.689424e-06 0.003246046 0.03354824 0.003246046 0.0010947642
#> sd.mc_std_err
#> 51 0.0010180263
#> 52 0.0010294378
#> 53 0.0010306991
#> 54 0.0010221373
#> 55 0.0010043809
#> 56 0.0009783155We compute the 95% prediction interval and the median as follows
inla.qmarginal(c(0.025, 0.5, 0.975), marginal = list(x = Nest$N, y = Nest$mean))
#> [1] 101.4321 130.2557 164.0649Compare Lambda to Nest by plotting: First
calculate the posterior conditional on the mean of
Lambda
Nest$plugin_estimate <- dpois(Nest$N, lambda = Lambda$mean)Then plot it and the unconditional posterior
ggplot(data = Nest) +
geom_point(aes(x = N, y = mean, colour = "Posterior")) +
geom_line(aes(x = N, y = mean, colour = "Posterior")) +
geom_ribbon(
aes(
x = N,
ymin = mean - 2 * mean.mc_std_err,
ymax = mean + 2 * mean.mc_std_err
),
fill = "grey",
alpha = 0.5
) +
geom_point(aes(x = N, y = plugin_estimate, colour = "Plugin")) +
geom_line(aes(x = N, y = plugin_estimate, colour = "Plugin")) +
ylab("pmf")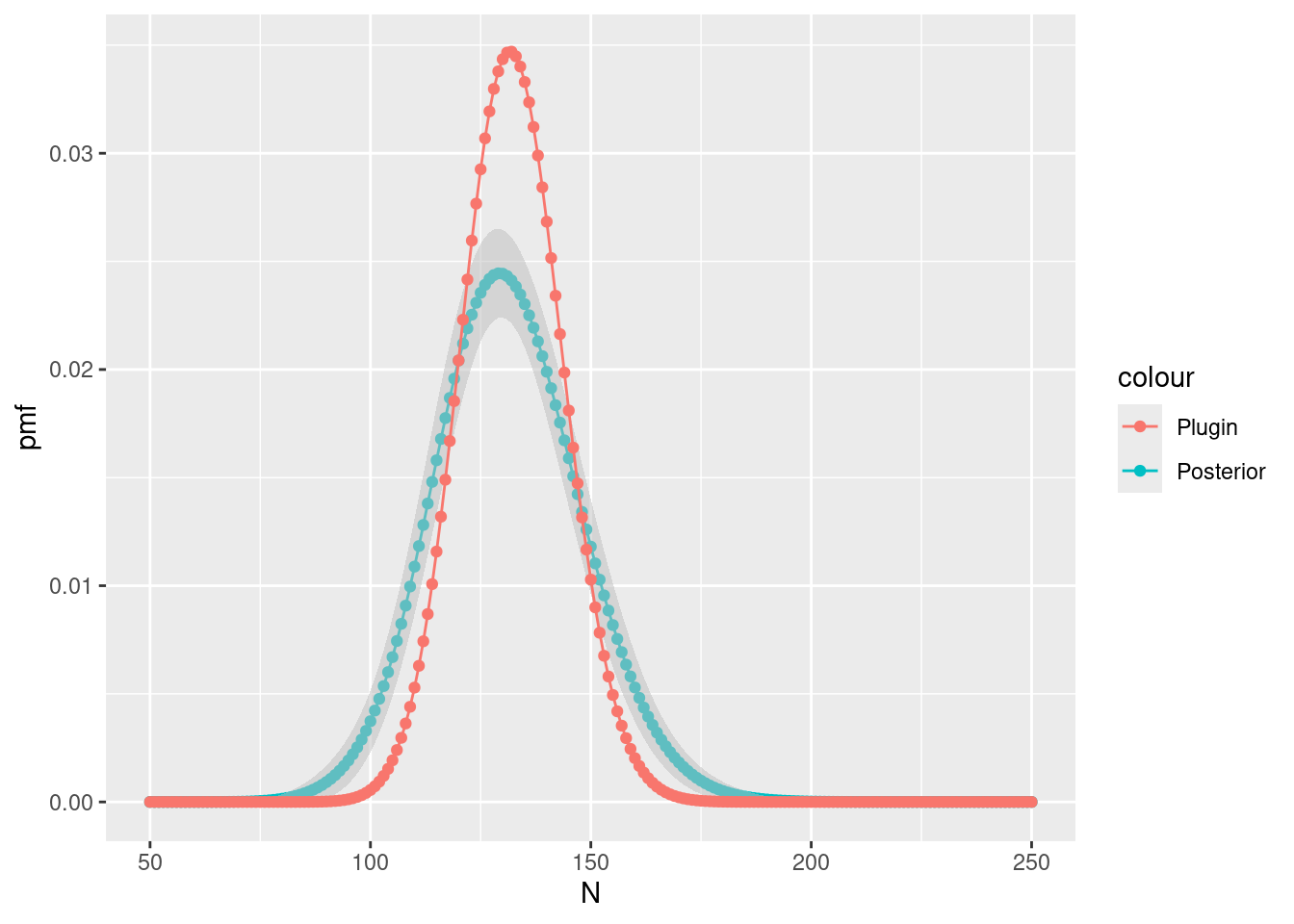
Do the differences make sense to you?
Comparison to GAM fit
Now refit a GAM for the count data of Poisson2_1D and
plot the estimated intensity function from this GAM fit, together with
the LGCP fitted above and the true intensity.
cd2 <- countdata2
fit2.gam <- gam(count ~ s(x, k = 10) + offset(log(exposure)),
family = poisson(),
data = cd2
)
dat4pred <- data.frame(
x = seq(0, 55, length = 100),
exposure = rep(cd2$exposure[1], 100)
)
pred2.gam <- predict(fit2.gam, newdata = dat4pred, type = "response")
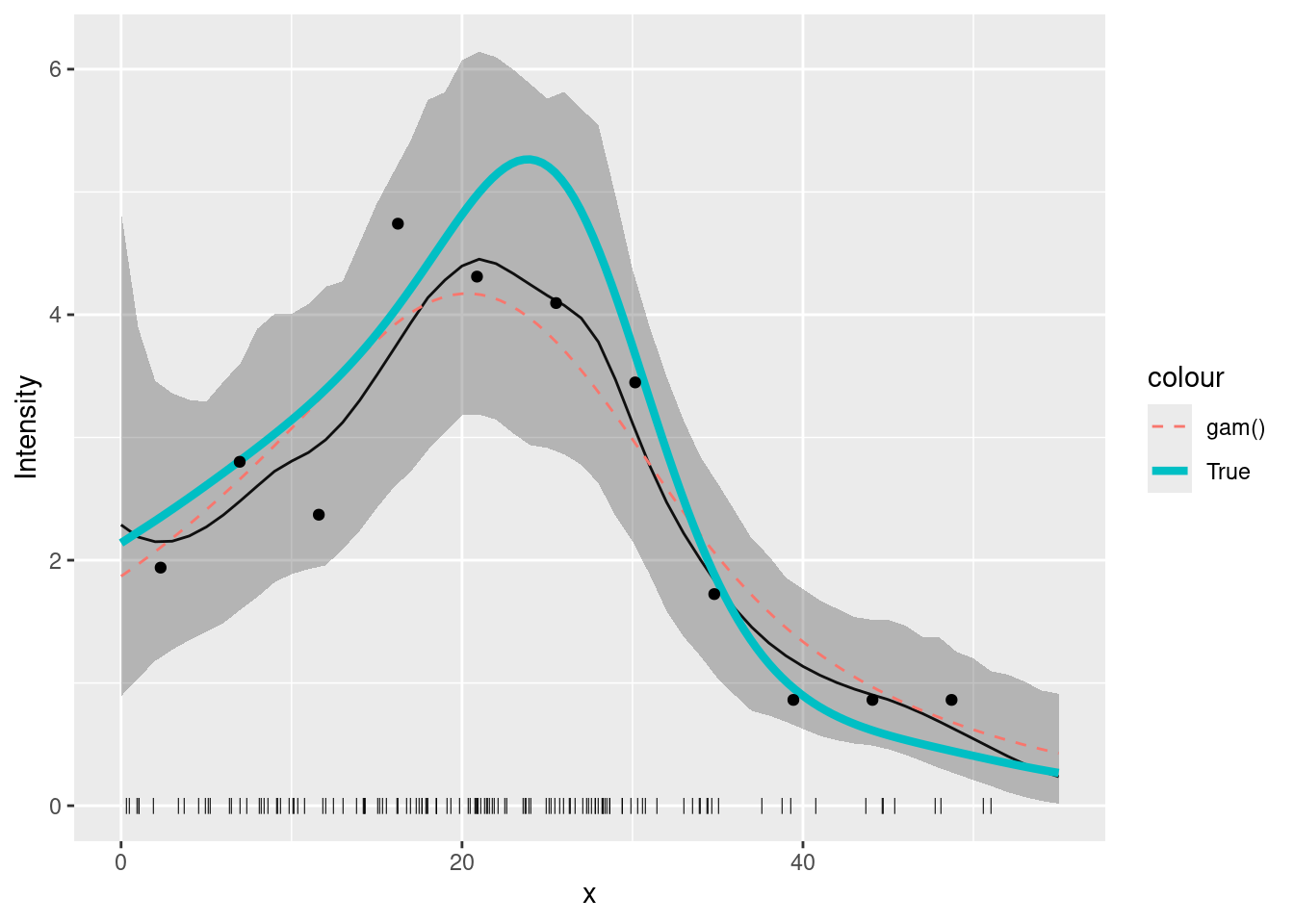
dat4pred2 <- cbind(dat4pred, gam = pred2.gam)You should get a plot like this (thick line is the true intensity, the thin solid line the inlabru fit, the dashed line the GAM fit:
plot(pred_spde) +
geom_point(data = pts2, aes(x = x), y = 0, pch = "|", cex = 2) +
geom_line(
data = dat4pred2,
aes(x, gam / exposure, colour = "gam()"),
lty = 2
) +
geom_line(data = true.lambda, aes(x, y, colour = "True"), lwd = 1.5) +
geom_point(data = cd2, aes(x, y = count / exposure)) +
ylab("Intensity") + xlab("x")